This chapter will explore how to store data in Google Cloud. We are going to cover the following storage types:
- Object storage – Google Cloud Storage
- Block storage – local and persistent disks for Compute Engine VMs and GKE
- File storage – Filestore
- Different types of databases – Cloud SQL, Cloud Spanner, Bigtable, Firestore, BigQuery, and Memorystore
Google Cloud provides multiple fully managed services for different types of application needs. Each section will look into a specific type of storage and their features, security, and availability. We will also cover the use cases of each category. Designing a storage strategy for cloud workloads is critical to ensure every application’s resiliency, performance, and response time.
Google’s object storage – Cloud Storage
Google Cloud Storage is a Google-managed, highly available, and durable object storage for storing unstructured immutable data such as images, videos, and documents. Its common use cases are website hosting, content storage and delivery, analytics, and backup and archiving.
All data stored in Google Cloud Storage is encrypted with Google- or customer-managed keys. The service is globally available and consistent, making it visible to all entitled users after a file is uploaded. In addition, there is no limit on the objects you can store. Each object includes data, metadata, and a unique identifier used to interact with it.
Objects stored in Google Cloud Storage are organized in containers called buckets. Buckets belong to a project and help organize and control data access. We can configure buckets to match the desired performance, availability, and cost efficiency.
This section will focus on designing Google Cloud Storage and working with objects stored in buckets.
One of the essential decisions when creating a Google Cloud Storage bucket is to choose where to store objects. For example, if objects are critical to our business, we may want to replicate them across regions for higher availability. Alternatively, if we have a latency-sensitive application that reads from our bucket, we may want to deploy a bucket in the same region where the application is running.
Once a bucket is created, it is not possible to modify its location. Therefore, it is important to have a clear understanding of the advantages and disadvantages of each option before making a decision.
Let’s look at the available location types for a Google Cloud Storage bucket to see how a geographic placement of a bucket determines its price, availability, and performance:
- A regional bucket is where objects are synchronously and automatically replicated between at least two zones in a single region. In the case of a zone failure, data is served from another zone. The failover and failback (once the region becomes available again) processes are transparent to users:
- Benefits: Lower price per GB than other location types, as you only pay for data in a bucket in one region. Also, you benefit from low latency and higher throughput if you run your Google Cloud workloads in the same region as your bucket. Furthermore, regional buckets are the only way to meet a company’s compliance policy to keep data within a particular country only
- Considerations: This location type doesn’t provide geo-redundancy (the distance between zones is less than 100 miles). Your objects won’t be available in the case of a regional failure.
- A dual-region bucket is where you provide geo-redundancy (more than 100 miles distance between data center locations) for your objects by specifying a pair of regions within the same continent between which objects will be replicated asynchronously (not in real time) by Google Cloud. There are three geographic areas: Asia, North America, and Europe, where you can select two regions for your bucket. The target for a default replication is one hour, but usually, it takes less than that. Turbo replication enabled between regions in a dual-region bucket will shorten the guaranteed replication time for newly written objects to 15 minutes. In addition, a failure in one region will not affect the availability of your objects. Again, this process is transparent to users and requires no additional setup for the failover and failback:
- Benefits: A dual-region bucket survives a failure in one of two regions. Also, you can define which regions out of the available ones you want to use for your bucket – for example, those closest to regions where you run your Google Cloud workloads or serve your content to users.
- Considerations: Not all regions are available for this location type yet. Also, you must pay per GB for two copies of data located in two regions and the replication traffic for write operations between buckets. The Turbo replication option is also subject to an additional fee. Furthermore, if most of your objects exist for a short time, the dual-region type would be of no benefit because object existence would be shorter than the replication window.
- Multi-region: This also provides a geo-redundancy within two or more regions in the following geographical areas: Asia, EU (zones in the European Union), and the US. The difference between a multi-region and dual-region type is that you can’t specify the regions for a multi-region bucket:
- Benefits: The price for a multi-region bucket is lower than for a dual-region one. Also, if you are serving content from a bucket to users in a whole geographic region such as the US and you can’t predict where your traffic is coming from, content served from a multi-regional bucket has the highest possibility of being close to users.
- Considerations: We allow Google to store data in different regions in a specified area (ASIA, US, or EU), and we don’t know which regions will be selected for each object. As a result, to access objects belonging to a multi-regional bucket, workloads running only in one region (for example, Compute Engine VMs in us-west2) will have to send requests across multiple US regions, impacting the service’s latency.
The following diagram summarizes how a location type choice can affect the object’s availability. There are three regions – Region A, Region B, and Region C – that belong to one geographical area, and three bucket locations – a regional bucket with one object (cat.jpg), a dual-region bucket with a replication set between Region A and Region B with a dog.jpg object, and a multi-region bucket with dino1.jpg, dino2.jpg, and dino3.jpg placed randomly across all regions, in two regions each:
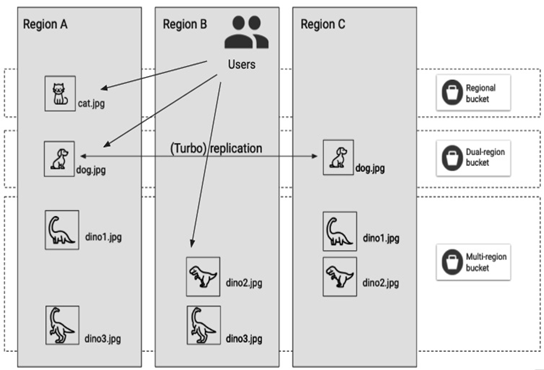
Figure 8.1 – A simplified diagram of an object placement for every Google Cloud Storage location type
When a disaster happens in Region A, users can still access objects in the dual-region and multi-region buckets, and they wouldn’t even be aware of a failure if not for the cat.jpg object, which was in the regional bucket and is now unavailable.
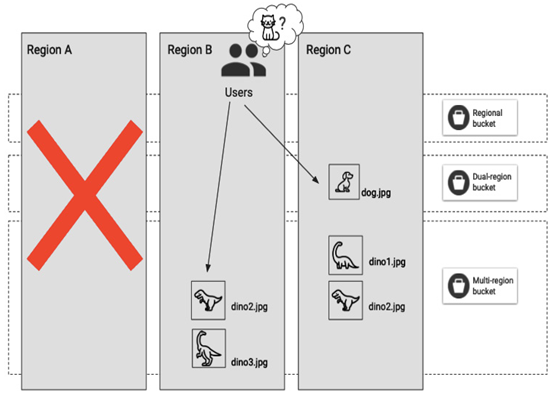
Figure 8.2 – A simplified diagram showing how Google Cloud Storage location type choice affects object availability in case of a failure in a region
To conclude, the location type can give objects stored in a bucket the required availability. So, even if we access an object once in 5 years, we may still want it to be highly available on the day we need it, so we configure such a bucket, for example, as dual-region.
But once we start storing objects in buckets, we will notice that their access patterns differ. Some of the objects are accessed frequently while, on the other hand, some buckets store archival data that is rarely accessed. Do we have to pay the same price per GB for objects we download every day and those we do once in 5 years? In the next section, we will explore possible savings on the buckets for infrequently accessed data.