There are limits to how much a relational database can expand. In most cases, it can only expand vertically. For example, you can grow Cloud SQL instances (described in the previous sections) by adding more storage or replicating to a larger instance up to the largest available type (vertical scaling), but to some point only, and not without performance sacrifices and downtime during migrations. Also, if a database needs to be reachable globally from applications requiring low latency, Cloud SQL can only provide regional read replicas for read-only operations.
Cloud Spanner is a Google-managed relational database service (with SQL schemas and querying) that can horizontally scale for reads and writes. Horizontal scaling is a method of increasing processing power and storage capacity by distributing the workload across multiple instances, unlike vertical scaling, which adds more resources to a single instance.
Furthermore, Cloud Spanner has global reachability as it can span across regions so that it can be accessed with low latency from all over the world. In addition, it meets the highest availability demands as it offers an SLA of up to 99.999% (roughly 5 minutes of downtime per year) for a multi-regional deployment. It doesn’t failover to a standby instance like Cloud SQL, but it elects a new leader out of available read-write replicas.
Spanner is located in the DATABASES section of the main menu of the Google Cloud console. When configuring an instance, you can choose the following configurations:
- The Regional option, which will create three read-write replicas in three separate zones within a chosen region. Regional configurations have 99.99% availability (roughly 50 minutes of downtime in a year) and low write latency within their region.
- The Multi-region option:
- Spans across the same continent, with two read-write replicas in two regions and one Witness location.
- Spans across the globe; for example, two read-write replicas in two regions of the same continent (the US), with one Witness replica (the US) and two read-replicas in the other two continents (Europe and Asia).
Note that a Witness replica’s role is not to serve reads but to form a majority quorum in case of a region’s loss. Multi-region configurations have 99.999% availability and low read latencies in multiple regions. The trade-off is increased write latency compared to Regional configurations, as the replication is synchronous and read-write replicas in separate regions need to vote on each write. Once a transaction is committed, it is written to all databases.
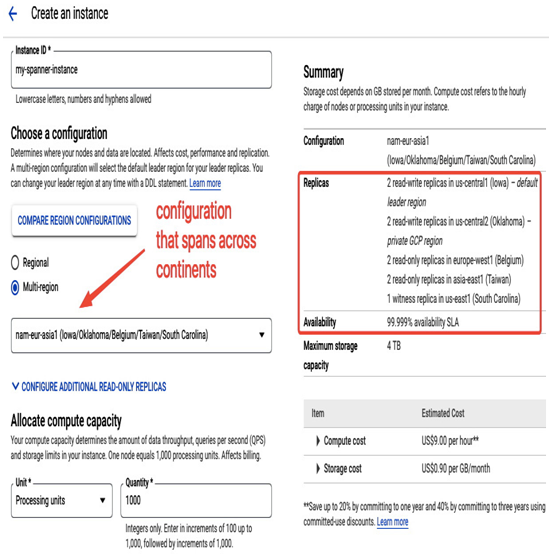
Figure 8.38 – Configuring a Spanner instance that spans globally
The following example presents how the replicas could be located when choosing the nam-eur-asia1 configuration, which spans continents. The global consistency for Spanner databases is achieved by utilizing Google’s low-latency global network and TrueTime, a global clock responsible for time synchronization across data centers:
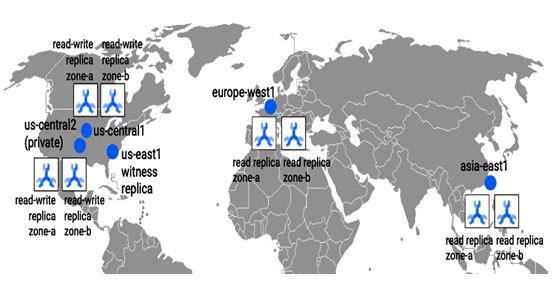
Figure 8.39 – Explanatory figure of Spanner node placements across the globe for the nam-eur-asia1 multi-region setup
In addition to Spanner’s location, you need to configure your instance compute and storage capacity by selecting either a required number of processing units or nodes (1 node equals 1,000 processing units). Each node equals 4 TB of storage with peak read and write performance per node being specific to a region. For example, for the nam-eur-asia1 setup, it is approximately 7,000 peak reads per region and 1,000 peak writes globally. Later, you can scale up or down your instance to add more resources or reduce the number of idle ones. This operation doesn’t require a maintenance window.
Similarly to Cloud SQL, Spanner supports point-in-time recovery for up to seven days, protecting data against accidental deletion or corruption. For longer-term retention, Spanner offers backups in the form of a transactionally consistent full copy of a database that can be stored for one year.
Non-relational databases (NoSQL)
Non-relational databases store data in an unstructured format. In contrast to SQL databases with a fixed schema, NoSQL databases store data as documents (JSON), key-value pairs, graphs, or dynamic-sized tables. Non-relational databases scale horizontally by adding new servers, making them a good fit for big data. Let’s look at the NoSQL database options that are offered by Google Cloud.