Applications designed for real-time banking, online interactive gaming with player scores and profiles, or geospatial processing all need the fastest possible response times. Databases such as Cloud SQL or Spanner still rely on disk operations, although they provide high throughput. To reduce its response latency to an absolute minimum, a database could be stored in memory directly by a processor.
Google Cloud offers a fully managed in-memory data store service called Memorystore for two open source caching engines: Redis and Memcached. Both can be used to build a cache for an application for heavily accessed data with sub-millisecond access to a dataset. In this section, we will focus on Redis.
Reduced latency is a huge benefit, but it doesn’t come without a trade-off. RAM is expensive and is available in smaller sizes compared to disks. That is why in-memory databases are kept closer to an application and used to accelerate an application response time, having a traditional, sizeable disk-based database at the backend.
Also, the in-memory database will not survive a node restart as memory is flushed in that process. Even though applications can be designed to populate cache from persistent disks to avoid downtime, Memorystore can be deployed with read replicas to which it can automatically failover. Also, Memorystore supports Redis Database RDB snapshots, which are point-in-time snapshots of a dataset.
When you provision a Redis instance, you provide the following: its name, location, the number of replicas, the VPC network that clients will use to connect to it, and its memory size. The more memory you provision, the higher throughput you will get.
There are two types of Memorystore for Redis:
- Basic tier, which you can deploy as a single Redis instance in a zone. It can serve as a simple cache, assuming an application that uses it can tolerate Redis data loss when this instance is restarted. The instance health is monitored, but there is no SLA.
- Standard tier, where instances of Redis are replicated across zones in a region. Up to five read replicas can be deployed. If you deploy an instance without a read replica, one replica will be deployed for high availability. Note that this replica won’t be enabled for reads. The Standard tier offers an SLA of 99.9% (roughly 9 hours per year). Multiple read replicas are used not only for availability but also to distribute the load of read operations. Each Redis instance is deployed with the primary endpoint that points to the primary replica and the read endpoint distributed among read replicas.
The following figure presents an example of Memorystore deployment options, where, with the Basic tier, only one instance can be deployed and accessed via an endpoint, and with the Standard tier, we can have one or more instance replica(s) used for high availability accessed via a primary endpoint. Additionally, we can utilize multiple replicas for reads, accessed via a read endpoint.
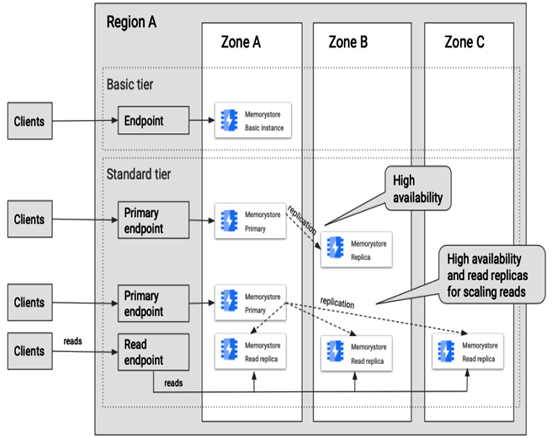
Figure 8.55 – Memorystore deployment options for the Basic and Standard tier
In the following screenshot, you can see the Memorystore section in the Google Cloud console. There is a Redis instance deployed in europe-central2 with 5 GB of capacity, a Standard tier with read replicas. It has two endpoints – Primary endpoint for read/write access and Read endpoint for scaling read operations:
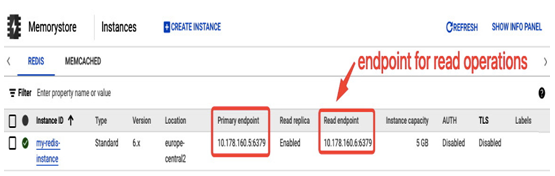
Figure 8.56 – Memorystore dashboard with a Redis instance
You can manage a Redis instance in the Google Cloud console using gcloud commands or client libraries in your code. You can control access to an instance via IAM. To connect to a Redis instance, a client should be in the same VPC as the instance, as it uses an internal IP. Alternatively, to connect to the instance from another VPC, a VPN service could be used.
Let’s assume you want to connect to an instance from a Compute Engine VM that uses the same VPC as your Redis instance. First, you need to deploy a redis-tools client:
sudo apt-get install redis-tools
To connect to an instance, use the following:
redis-cli -h 10.178.160.5
Here, the IP address is the one presented in the Memorystore dashboard for this instance.
You can run redis-benchmark to generate some workload:
redis-benchmark -h 10.178.160.5 -q
The following figure presents a monitoring chart of this instance with calls that the preceding benchmark command triggered to test the database performance. It’s very convenient to have observability built into a database service because it allows for closer monitoring and troubleshooting of any issues that may arise:
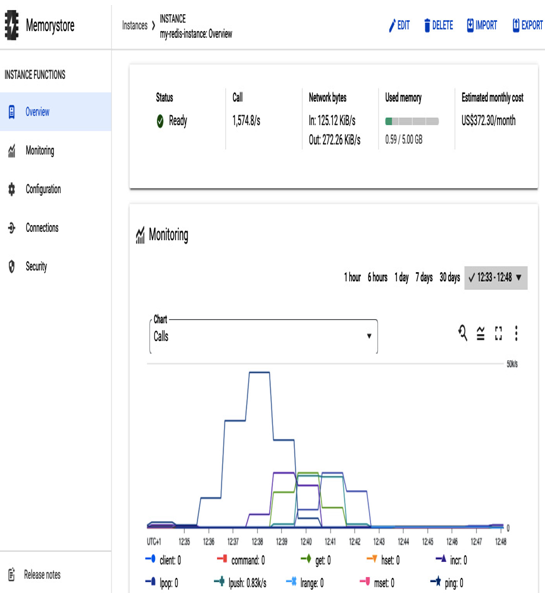
Figure 8.57 – A Redis instance dashboard with a monitoring chart
The preceding screenshot presents a Monitoring dashboard with client calls during redis-benchmark tests.
This chapter explored various ways that data can be stored in Google Cloud. Let’s summarize what we have learned about storage.
For large amounts of unstructured data, we could use Google Cloud Storage. Applications installed inside Compute Engine VM will benefit greatly from performant local or persistent drives. If files need to be shared between users over a network, Filestore will be the best fit. If data that we store for an application is structured and can be organized in tables, relational databases such as Cloud SQL or Spanner will make a good choice, with Spanner being able to scale horizontally better. If the data is not relational but of the key-value type, Cloud Bigtable is a perfect use case. Firestore is the best fit if you are looking for a document database for mobile applications. BigQuery would be the best for analyzing large amounts of unchanged data.
Please refer to the following diagram, which will hopefully assist you in identifying the differences between the database solutions discussed in this chapter:
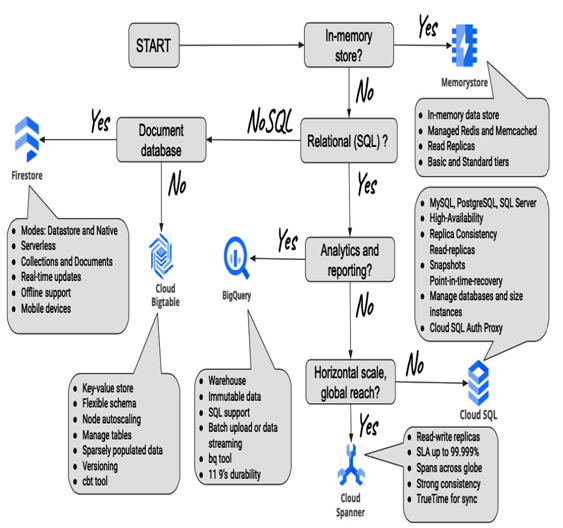
Figure 8.58 – Selecting the right database, a decision tree with keywords that summarize features of databases in Google Cloud
As you may have noticed, we also briefly discussed networking when exploring accessing databases and storage. Moving forward, in the upcoming chapter, we will delve deeper into the world of networking and explore its intricacies.