Imagine you need to design an application that continuously scans the state of millions of IoT sensors, or that the service you are designing will be responsible for keeping track of a few million users’ behaviors and offering them recommendations based on their preferences. In such scenarios, you will have to store data in a low-latency database. Still, the data model must be flexible because data structures could change over time: upgraded IoT devices storing an additional set of parameters could be introduced, or a new service could be integrated with your recommendation engine. Therefore, such a database should be able to store large amounts of rapidly changing and constantly growing data. Also, it should retrieve data within single-digit milliseconds as everyone expects to get results in real time. On the other hand, high throughput demands could be seasonal, so such a database would have to be able to scale up and down based on load for cost optimization.
Cloud Bigtable is a good fit for such cases. It is a fully managed, key-value, and wide-column NoSQL database designed to store petabytes of data and scales well, offering low latency reads and writes. A Cloud Bigtable instance is a container that hosts clusters deployed in one or many regions. Clusters consist of nodes that define the performance of an instance. You can add or remove nodes manually via autoscaling without downtime. Inside an instance, we can create tables. With Bigtable, we manage tables, not a database itself.
The cost optimization of Cloud Bigtable comes not only from the ability to scale up and down. In addition, tables in Bigtable are sparse, which means they don’t need to store entries in every cell. Because there is no charge for empty cells, savings can be significant, especially when such a database scales to an enormous number of rows and columns.
The IoT service or the recommendation engine from our example could also benefit from Cloud Bigtable’s versioning, which can help, for example, with time series analysis. Cells in tables may not only be empty but they can also have different values at different time points. Each time data is written to a cell, it is timestamped, so when new data is written to the same cell, the old one is not overridden. You can enable a garbage collection to delete older versions when they are no longer needed and reclaim this space.
You can increase the availability of a Cloud Bigtable instance by replicating it to clusters in other regions. The replication in the same cluster within nodes is strongly consistent, but eventually consistent between clusters. This means that it can take some time between when data is written to one cluster and the time it can be read from another.
To protect data in tables, you can use backups stored on the cluster that owns a table and keep it for up to 30 days.
Cloud Bigtable is a non-relational database, so it might be not easy to use it for analytics operations as it doesn’t support joins and aggregations. However, for analyzing data stored in Cloud Bigtable, leverage its integration with BigQuery.
You can work with an instance and create tables and backups in the Google Cloud console. But to interact with tables, you will have to use client libraries (HBase Java Client, Go, and Python Client), HBase Shell, or cbt, a command-line tool for performing operations on Cloud Bigtable. The cbt tool can be installed as a gcloud CLI component or launched from Cloud Shell.
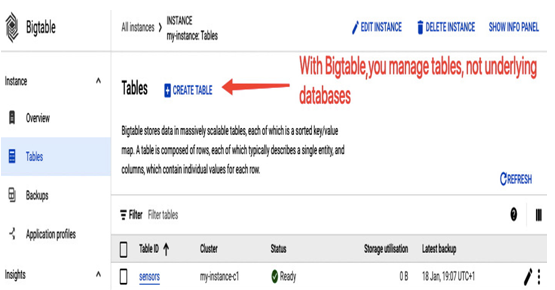
Figure 8.40 –Creating a Bigtable table via the Google Cloud console
To download cbt to your workstation, use the following command:
gcloud components install cbt
You can configure cbt to use your project by editing the cbtrc configuration file:
echo project = my-demo-project-xxx >> ~/.cbtrc
A Bigtable instance can be created via the Google Cloud console or cbt. The user interface equivalent of creating an instance would be the following:
cbt creanteinstance
To create a my-instance instance in the us-central1 region that runs on three nodes and uses SSD storage, use the following:
cbt createinstance my-instance “My instance” my-instance-c1 us-central1-b 3 SSD
Once my-instance is created, you need to update the cbtrc file for cbt to use this instance:
echo instance = my-instance >> ~/.cbtrc
The following figure shows the command-line output from the creation of a Bigtable instance using the aforementioned steps:
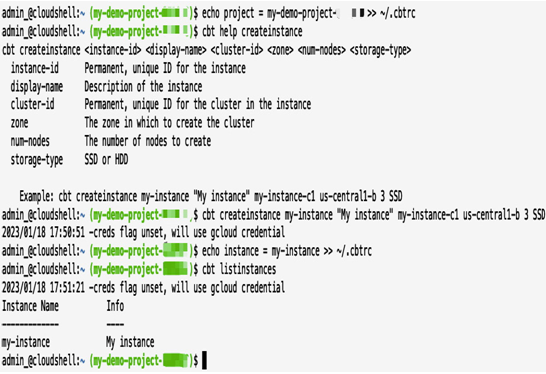
Figure 8.41 – Creating a Cloud Bigtable instance with the cbt tool
Let’s use my-instance to create an example table that stores information about room temperature from sensors:
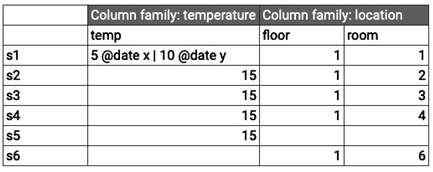
Figure 8.42 – A table that stores the temperature and location of sensors
To create a table using cbt, run the following command:
cbt createtable sensors
Bigtable organizes data in column families, which are columns often used together, such as location, floor, and room. It helps to organize the data and limits the amount of pulled data. We will create two column families – temperature and location:
cbt createfamily sensors temperature
cbt createfamily sensors location
Then, we can provide values that match the values in the table in Figure 8.42. Note that you don’t have to provide values for all the column families:
cbt set sensors s1 temperature:temp=5 location:floor=1 location:room=1
cbt set sensors s2 temperature:temp=15 location:floor=1 location:room=1
cbt set sensors s3 temperature:temp=15 location:floor=1 location:room=1
cbt set sensors s4 temperature:temp=15 location:floor=1 location:room=1
cbt set sensors s5 temperature:temp=15
cbt set sensors s6 location:floor=1 location:room=1
Use cbt read sensors to read the data from the table.

Figure 8.43 – A part of the output of the cbt read command that shows multiple values for the same cell
Now, let’s say we update the temperature value for the s1 sensor to 10:
cbt set sensors s1 temperature:temp=10
We will see both temperature values with timestamps, as presented in Figure 8.43.
The following figure shows a screenshot of a section of a database output (for the s4, s5, and s6 sensors) after we added values to columns for our sensors. Note that the table is sparse, so for the s4 sensor, we have values for each of the columns (floor, room, and temp) but the s5 sensor has only a value for temp, and the s6 sensor only has values for floor and room.
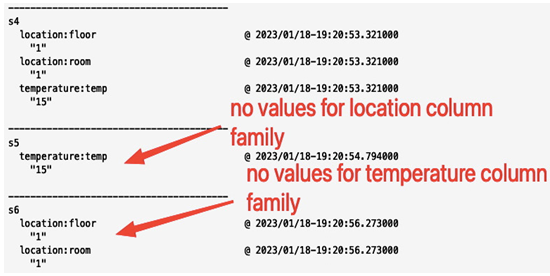
Figure 8.44 – A part of the output of the cbt read command showing that not all cells have values
Now that we looked into the key-value NoSQL database, let’s see a different type of NoSQL type, which is a document store.