Block, file, or object storage are not the only solutions to store data. Data can also be stored in databases: relational SQL databases and non-relational NoSQL databases. Both types will be covered in the next sections. Also, we will look into a data warehouse and in-memory database:
While looking for a database that will be the best fit for a solution, we consider the following requirements:
- Availability: Can an application accept that data is unavailable or available with a certain delay? Should it be regional (such as Cloud SQL), multi-regional, or span continents such as Spanner?
- Scale: How much data will be stored? For example, terabytes in a CloudSQL instance or petabytes with a Spanner instance.
- Performance: Is it a database for real-time systems or analytics? How fast should a database process read and write operations? How many regions will it have to serve? (If copies of a database are spread across regions, it may introduce some latency to write operations. This is a trade-off for maintaining strong consistency, like with Spanner). How can database performance be improved? For example, can we add more nodes?
- Consistency: In the case of database replication between regions, does the data written in one region have to be immediately available in another one?
- Functions: What are some additional features a database can offer? What form of a database backup is available?
- Cost: Does a solution need to be cost-optimized? For example, can it scale down when a larger capacity is no longer required?
In the next sections, we will look into database solutions offered by Google Cloud and discuss the requirements we just listed.
Data stored in relational databases is structured ahead of time and organized in tables with a static schema. Relational databases scale vertically by adding more compute and storage resources to the server where they run or by migrating to a larger server instance. To query and manipulate data in a relational database, a SQL programming language is used. The strength of relational databases is that they are designed for operations such as aggregations, sums, or multi-row transactions.
Google Cloud offers the following relational database services: Cloud SQL and Cloud Spanner, which we will cover in this section.
Cloud SQL
Cloud SQL is a relational database service that offers three engines – MySQL PostgreSQL, and Microsoft SQL Server. It has a built-in integration and can be used as a backend for other Google Cloud services such as Compute Engine, GKE, and Cloud Run. In addition, the integration with Google’s serverless data warehouse, BigQuery (which will be covered later in this chapter), allows you to run federated queries to your Cloud SQL databases from BigQuery directly.
Each Cloud SQL instance is powered by a VM deployed in a Google-managed environment, and Google is responsible for its availability, updates, and patching. You can choose the amount of CPU, RAM, and storage for your instance according to the performance you need. CPU and RAM resources can be adjusted in time up to the maximum values a VM can offer, but it requires an instance shutdown. On the other hand, storage can be increased while an instance is running.
To handle more data or queries, you can increase the single VM capacity of your current instance by adding additional resources. This is called vertical scaling.
An instance is a resource pool for your databases. Once an instance is deployed, you can create databases that will run inside.
Assigning a Public IP to your instance will make it accessible from the outside of your environment. Alternatively, Cloud SQL can only connect to your internal network when it is configured with a Private IP. In addition, Cloud SQL has built-in encryption, both at rest and in transit.
Cloud SQL can be deployed in multiple zones within a selected region to achieve high availability. Furthermore, as data is replicated synchronously, when a failure occurs in a primary zone, a database will be served automatically from a secondary zone without data loss and the need to reconfigure applications connecting to an instance.
Use on-demand or scheduled backups to protect your Cloud SQL databases. Backups can run during a provided maintenance window. Also, there is an option to enable point-in-time recovery and recover data from a point in time, thanks to storing transaction logs.
In scenarios where you expect database traffic to come from different regions or need extra processing for analytics, leverage another Cloud SQL feature – read replicas. Read replicas are read-only copies of an original database that can be placed in the same or a different region, close to users. Read replicas can also be used to migrate a database to a different region or a larger instance.
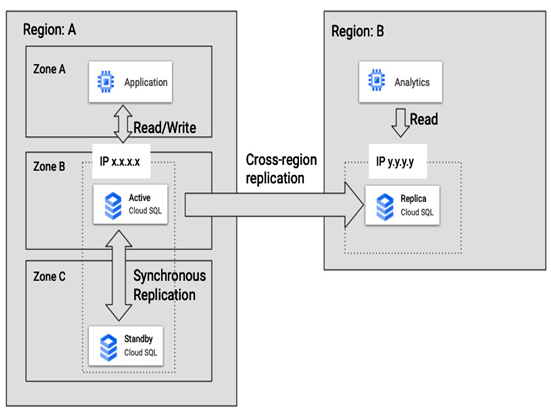
Figure 8.26 – Example use case of Cloud SQL high availability with a read replica located in another region
The preceding example presents how high availability and read replica features can be used together. An application in Region A and Zone A inserts data into a Cloud SQL database in Region A and Zone B; both run in the same region to minimize latencies. The SQL instance works in high availability mode, so the data is synchronously replicated to another zone, Zone C. In the case of Zone B failure, data will be served from the same IP (x.x.x.x) from the instance in Zone C. There is also a read replica instance in another region, Region B, where data is replicated. An analytics application, also located in Region B, reads data directly from a read replica served from a different IP, y.y.y.y. This approach offloads analytics traffic from the original instance and allows it to be served from a copy closer to the analytics application. In the case of a failure in Region A, the read replica in Region B can be promoted to a standalone primary instance.
Let’s summarize what we have learned about Cloud SQL by going through the following example.