To understand Pub/Sub, we need to list several key service components:
- Message: Data that flows through the service.
- Topic: A named entity that represents a feed of messages.
- Subscription: A named entity that receives messages on a particular topic.
- Publisher: Also called a producer, the publisher creates messages and publishes them to the messaging service on a specific topic.
- Subscriber: Also called a consumer, the subscriber receives messages on a specific subscription.
The following is a visual representation of the architecture:
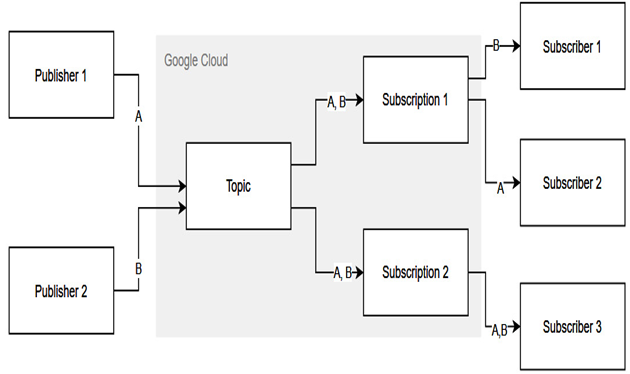
Figure 10.1 – Pub/Sub architecture
The preceding diagram shows two publishers – A and B – sending messages to a topic. The topic has two subscriptions that want to receive messages from the topic. On the right-hand side, subscribers receive messages from the specific subscription. We can also see that subscribers receive different messages. Some subscribers receive only message A or B, but Subscriber 3 receives both A and B.
Pub/Sub combines the horizontal scalability of Apache Kafka and Pulsar with features found in traditional messaging middleware such as Apache ActiveMQ and RabbitMQ.
Pub/Sub integrates with other Google Cloud services such as Dataflow, Logging and Monitoring, triggers, notifications, and webhooks.
In the next section, we will learn about Dataproc – one of the next data processing services in Google Cloud.
Dataproc is a fully managed Google Cloud service that runs Apache Hadoop, Apache Spark, Apache Flink, Presto, and more than 30 other open source tools and frameworks. It can be used for data lake modernization, Extract, Transform, and Load (ETL) operations, and data science.
One advantage of using Dataproc is that there’s no need to learn new tools or APIs. Dataproc allows us to start, scale, and shut down; each operation takes 90 seconds or less. Creating a cluster might take 5 to 30 minutes compared to on-premises deployments. Dataproc integrates with other Google Cloud services such as BigQuery, Cloud Storage, Cloud Bigtable, Cloud Logging, and Cloud Monitoring. This creates a data ecosystem that is easy to use, regardless of how you interact with it – the Google Cloud console, Cloud SDK, or REST API.
By default, Dataproc supports the following images:
- Ubuntu
- Debian
- Rocky Linux
To learn which exact versions of images are supported, go to https://cloud.google.com/dataproc/docs/concepts/versioning/dataproc-version-clusters#supported_dataproc_versions.
Dataproc architecture
Google Cloud allows you to run Dataproc on Google Compute Engine (GCE) or Google Kubernetes Engine (GKE). The main difference between Dataproc on GCE versus Dataproc on GKE is that Dataproc on GKE virtual clusters does not include separate master and worker VMs. In Dataproc on GKE, a node pool is created within the GKE cluster, and jobs are run as pods on these node pools:
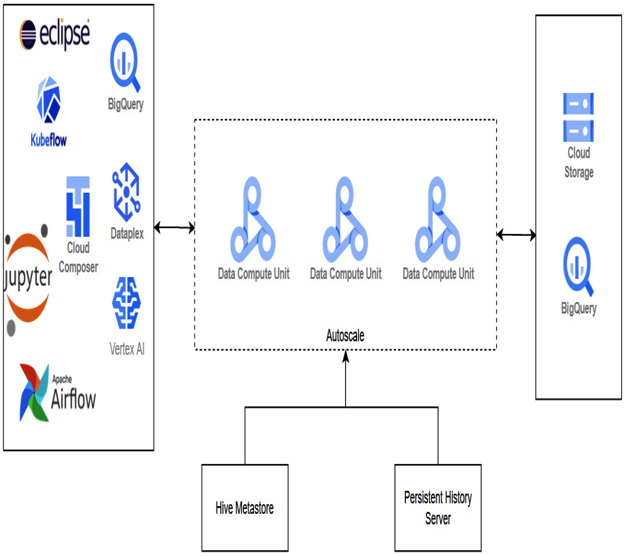
Figure 10.2 – High-level Dataproc architecture
The preceding diagram shows a high-level overview of the Dataproc architecture. On the left-hand side, we have possible sources of the data. In the middle section, we have data computing units that leverage autoscaling policies. If your job requires more compute units, you can configure autoscaling policies. You can store the results of the jobs in Cloud Storage or BigQuery.
The following section will discuss the next Google Cloud offering – the Dataflow data portfolio product.