As data grows out of datasheets, it needs a more efficient system for its analytics – a data warehouse. However, scaling and managing such a platform on-premises can be challenging, especially when data grows from gigabytes to terabytes and petabytes. Such challenges are addressed by the Google-managed serverless data warehouse: BigQuery.
This is a query engine designed to handle massive amounts of data with no limit to the amount of data that can be stored. In addition, BigQuery supports SQL queries and is a good choice for table scan tasks and cross-database queries.
It owes its horizontal scalability to storage and compute separation. Although storage and compute layers are decoupled, it doesn’t impact the speed of data access, thanks to Google’s fast networking. Also, it is highly durable (with eleven nines of durability, the chance of data loss is almost 0) as it replicates data across zones. Still, its whole internal architecture is hidden from users as BigQuery is serverless.
Data in BigQuery is organized in containers called datasets, which are top-level folders that organize and control access to underlying tables:
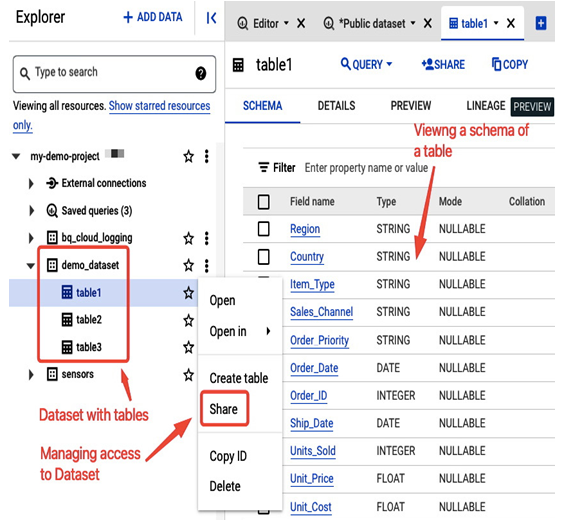
Figure 8.50 – BigQuery Explorer view in the Google Cloud console with example dataset with tables
BigQuery is integrated with Google’s IAM service so you can manage read/write access to datasets for users and groups, enabling their collaboration on shared data. For example, a predefined BigQuery Data Viewer role lets you view a dataset’s details. A BigQuery Data Editor role allows you to create, update, and delete dataset tables. A user with BigQuery Job User role has the ability to execute various jobs, such as running queries, within the whole project.
Data stored in BigQuery is encrypted before being written onto disks. The encryption is done using either Google-managed or customer-managed encryption keys.
You can import data to BigQuery in the following ways:
- If your data will not change, it can be loaded once as a batch operation. For example, you can use a file in a CSV format and let BigQuery auto-detect its schema. Data can be uploaded from a local machine, Google Cloud Storage, or Cloud Bigtable. You can also upload data from object storage from other cloud providers.
- If your data changes occasionally (for example, once a day), you can use the Data Transfer feature of BigQuery and load data on schedule from other Google services or external storage or warehouse providers.
- If data needs to be analyzed in real-time, some options would be to stream data to BigQuery via the Storage Write API or Dataflow, a Google Cloud serverless service for unified stream and batch data processing (for more information on Dataflow, check Chapter 10.
Once raw data is loaded, it can be used as staging data for further processing.
You can interact with BigQuery via the Google Cloud console or bq, a Python-based command-line tool from the gcloud CLI. It also supports client libraries for Python, Java, and Go. Alternatively, you can use the REST API or third-party tools for further integration.
The following screenshot presents the BigQuery Explorer view, where you can create datasets and tables, import data to a table, and run SQL queries:
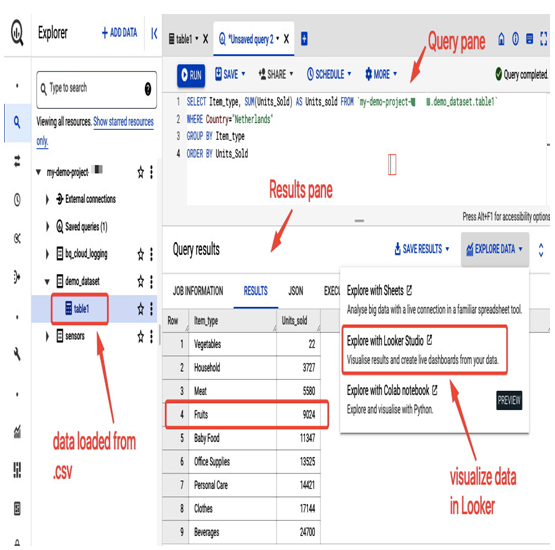
Figure 8.51 – Example SQL query on a table containing imported data from a CSV file
Data can be further visualized in Looker Studio, a platform where you can explore data and build charts based on various metrics and filters, narrowing down the dataset:
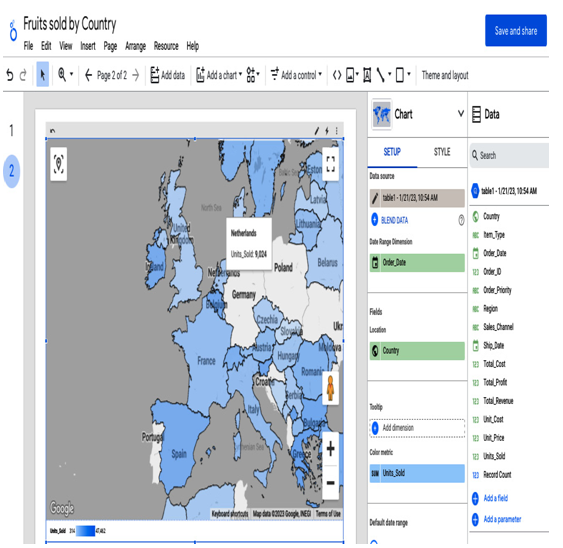
Figure 8.52 – Google Maps-style dashboard in Looker visualizing the query from Figure 8.51
You can practice SQL queries in BigQuery on a public dataset: bigquery-public-data. Please refer to the documentation for detailed instructions on how to use public datasets: https://cloud.google.com/bigquery/docs/quickstarts/query-public-dataset-console.
Please refer to the following screenshot for an example of how to query the public dataset’s bigquery-public-data.san_francisco_film_locations.film_locations table to search for information regarding the filming locations of a popular movie that was shot in San Francisco:
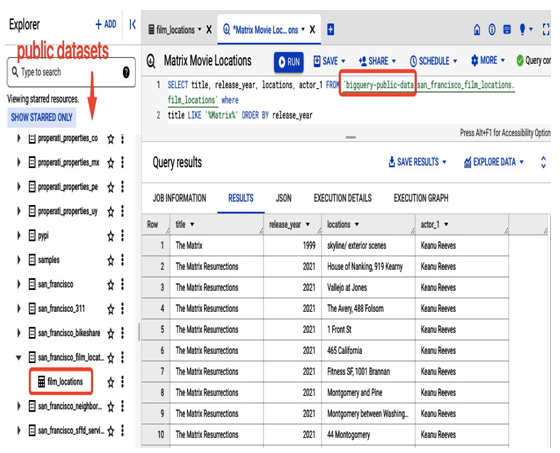
Figure 8.53 – Practicing SQL queries on the public dataset
To build queries, you can also use Cloud Shell, which has the bq command-line tool installed. In addition to the Google Cloud console, this is another option available to you. Simply run the bq ls command to list the available datasets. To construct your queries, use the following format:
bq query –use_legacy_sql=false ‘SELECT title, release_year, locations, actor_1 FROM `bigquery-public-data.san_francisco_film_locations.film_locations` where title LIKE “%Matrix%” ORDER BY release_year’;
The following screenshot presents the Cloud Shell console view where the similar command is issued:

Figure 8.54 – Practicing the bq command-line tool
Now, let’s look into the last storage option of this chapter. It is a totally different kind of database than we have investigated so far. This one is optimized to provide the lowest response times.